Data For Exploration Data packages Selected Digitized Books Data Package
Selected Digitized Books Data Package
This dataset comprises 84,058 files containing full text from 90,414 books in the Selected Digitized Books collection on loc.gov. The text was created as part of digitization workflows using Optical Character Recognition (OCR) technologies.

About this dataset
This dataset comprises 84,058 files containing full text from 90,414 books in the Selected Digitized Books collection on loc.gov. The text was created as part of digitization workflows using Optical Character Recognition (OCR) technologies. The dataset was created using the loc.gov JSON/YAML API to fetch the metadata and an internal workflow processing and data management application to pull the associated full text from an LCCN. The metadata comprises all of the selected digitized books (as of 2022-08-26) that had a date associated with the item record.
| Metadata | Metadata formats | Data files |
|---|---|---|
| 90,414 records | .csv, .json | 84,058 full text files (.txt, .json) |
Data package documentation
Included in this data package is comprehensive documentation of source data or collection provenance, the contents of the data package, and how the data package was created. Here are some particular sections of interest as well as a link to the full documentation:
- About the source data or collection
- Computational readiness and possible uses
- How was it created?
- Dataset field descriptions
Dataset at a glance
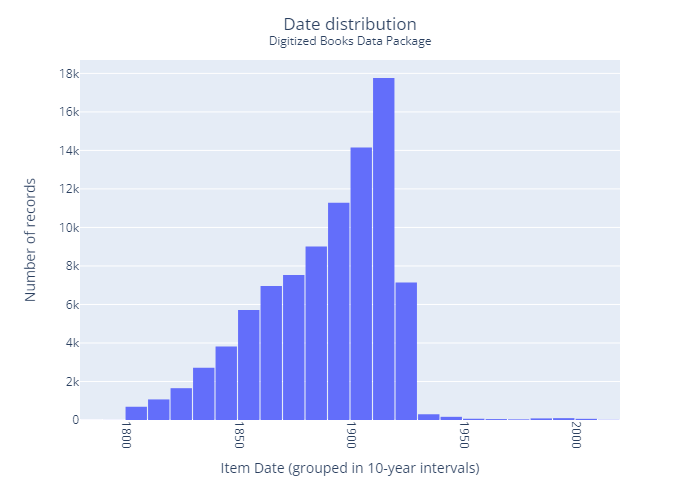
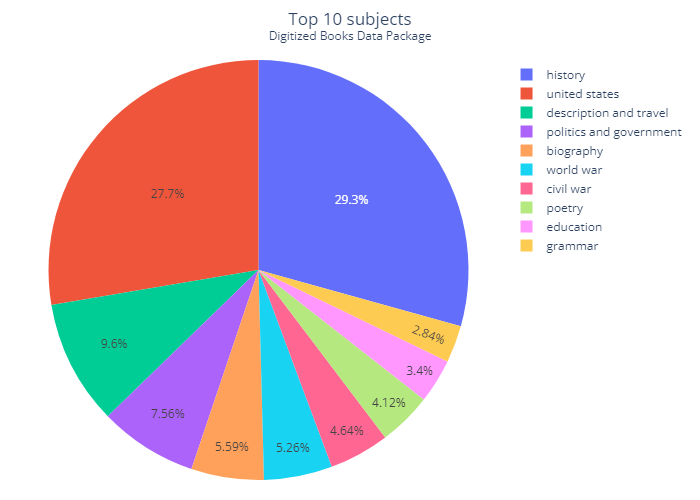
How to access and use this data package
There are two main options for accessing and using this data package: (1) Directly downloading files from this page and (2) using Python for more advanced usage.
Direct downloads
The following list outlines the contents of this data package. Many of the individual files inside the data package are linked directly on this page which you can download and immediately use. Zipped files are available for bulk download of the entire or parts of the data package.
| Sample the data |
|
|---|---|
| Download the documentation |
|
| Download the metadata |
|
| Download the OCRed text |
|
Using Python
While direct downloads are more convenient for most activities, users with familiarity with writing Python can perform more advanced and complex tasks programmatically.
For your convenience we developed a number of Jupyter Notebooks to help get you started.
View the Python notebook for this data package
Bulk downloads using Python
For bulk downloads, refer to this Python script for downloading files in bulk . Sample commands for this data package:
Download all OCR'd text data
python bulk_download.py --package
"https://data.labs.loc.gov/digitized-books/" --out "output/digitized-books/"
Dataset details
| Source collection |
Selected Digitized Books collection The Selected Digitized Books collection is a growing collection of selected books and other materials from the Library of Congress General Collections that have been made openly available. Most of the materials in this collection were published in the United States prior to the 1930s and are in English. The collection features thousands of works of fiction, including books intended for children, young adults, and other audiences. There are also some materials in foreign languages that were published in other countries. |
|---|---|
| Rights statement |
The books in this collection are in the public domain and are free
to use and reuse.
Credit Line: Library of Congress More about Copyright and other Restrictions . For guidance about compiling full citations consult Citing Primary Sources . |
| Date created | 2022-09-27 |
| Date updated | 2024-04-03 |
| Creators & contributors |
|
| Cite this dataset |
|
| Curatorial questions | For curatorial questions about the content of the collection or technical questions about the dataset formats and composition, please contact the Main Reading Room via the Library's Ask a Librarian service at https://ask.loc.gov/history-humanities-social-sciences/ . |
| Access questions | For questions and technical issues about download and access, please submit a ticket on Github or email the LC Labs Team at [email protected] . |